
自宅のRaspberry Piに OpenClaw(旧Clawdbot / Moltbot)を構築し、LAN上のローカルLLMサーバー、Google Gemini API、Discordチャンネル、Webダッシュボードをひととおり動かすところまで持っていった記録。
設定ファイルのエラーや、TailscaleでのDashboardアクセスまで、ひっかかったポイントを全部残しておく。
環境
| 項目 | 内容 |
|---|---|
| ボット機 | Raspberry Pi(Debian arm64 / ホスト名: pibot) |
| OpenClaw | 2026.2.26 |
| LLMサーバー | MINISFORUM HX370(CachyOS Linux)/ llama-server(Qwen3.5-35B) |
| LLMサーバーIP | xxx.xx.xxx.xxx:11434(Tailscaleネットワーク内) |
| モデルファイル | Qwen3.5-35B-A3B-UD-Q4_K_XL.gguf |
| クラウドモデル | Google Gemini API(AI Studio APIキー) |
| チャンネル | Discord |
| リモートアクセス | Tailscale Serve |
OpenClawの完全再インストール
前回の失敗した設定が残っていたため、まずクリーンな状態から始めた。
# 設定ディレクトリを削除
rm -rf ~/.openclaw/
# アンインストール
npm uninstall -g openclaw
# 最新版をインストール
npm install -g openclaw@latest
# オンボーディングウィザードを実行
openclaw onboard --install-daemon
--install-daemon を付けるとsystemdサービスとして登録されるため、Pi再起動後も自動起動する。
LANのllama-serverに接続する
llama-server側の起動コマンド(参考)
MINISFORUM HX370側では以下のパラメータで起動している。
./build-vulkan/bin/llama-server \
-m ./models/Qwen3.5-35B-A3B-UD-Q4_K_XL.gguf \
-ngl 99 \
-n -1 -c 65536 \
--flash-attn on \
--cache-type-k q8_0 --cache-type-v q8_0 \
--temp 1.0 --top-k 20 --top-p 0.95 \
--min-p 0.0 --presence-penalty 0.0 --repeat-penalty 1.0 \
--jinja \
--reasoning-format none \
--batch-size 512 --ubatch-size 512 \
--host 0.0.0.0 --port 11434
主なパラメータの意味:
| パラメータ | 内容 |
|---|---|
-ngl 99 |
GPUにオフロードするレイヤー数(全レイヤーをGPUに載せる) |
-c 65536 |
コンテキスト長64k tokens |
--flash-attn on |
Flash Attentionで高速化・VRAM削減 |
--cache-type-k/v q8_0 |
KVキャッシュをq8量子化(VRAM節約) |
--jinja |
Jinjaテンプレートエンジンを有効化 |
--reasoning-format none |
reasoning出力を無効化 |
--batch-size 512 --ubatch-size 512 |
プロンプト処理のバッチサイズ |
openclaw.jsonへのカスタムプロバイダー設定
~/.openclaw/openclaw.json の models.providers に以下を追記する。
"models": {
"mode": "merge",
"providers": {
"custom-llm-server": {
"baseUrl": "http://xxx.xx.xxx.xxx:11434/v1",
"apiKey": "llama-local",
"api": "openai-completions",
"models": [
{
"id": "Qwen3.5-35B-A3B-UD-Q4_K_XL.gguf",
"name": "Qwen3.5-35B-A3B-UD-Q4_K_XL.gguf (Custom Provider)",
"reasoning": false,
"input": ["text"],
"cost": { "input": 0, "output": 0, "cacheRead": 0, "cacheWrite": 0 },
"contextWindow": 65536,
"maxTokens": 8192
}
]
}
}
}
ハマりポイント:api は openai-completions を使う
openai-responses を指定するとsystem promptがサイレントに欠落するバグがある。llama-serverやOllamaと接続する場合は必ず openai-completions を使うこと。
ハマりポイント:contextWindowが足りないエラー
Error: Model context window too small (4096 tokens). Minimum is 16000
オンボーディング後に contextWindow が 4096 になっていることがある。手動で修正する。
# 確認
openclaw config get models.providers.custom-100-72-129-123-11434.models
# または直接 openclaw.json を編集して contextWindow を 32768 に変更後
openclaw gateway restart
Google Gemini APIを追加する
openclaw onboard --auth-choice gemini-api-key
ウィザードが起動するので、Google AI StudioのAPIキーを入力する。
openclaw.jsonへのGeminiプロバイダー設定
"google": {
"baseUrl": "https://generativelanguage.googleapis.com/v1beta",
"api": "google-generative-ai",
"models": [
{
"id": "gemini-3.1-pro-preview",
"name": "Gemini 3.1 Pro Preview",
"reasoning": true,
"input": ["text", "image"],
"cost": { "input": 2, "output": 12, "cacheRead": 0.2, "cacheWrite": 0 },
"contextWindow": 200000,
"maxTokens": 8192
},
{
"id": "gemini-3-flash-preview",
"name": "Gemini 3 Flash Preview",
"reasoning": true,
"input": ["text", "image"],
"cost": { "input": 0.5, "output": 3, "cacheRead": 0, "cacheWrite": 0 },
"contextWindow": 1000000,
"maxTokens": 8192
}
]
}
gemini-3-pro-preview は2026年3月9日に廃止予定。gemini-3.1-pro-preview に移行すること。OpenClaw 2026.2.26時点ではカタログに未登録なので、上記のようにmodelsに直接定義する必要がある。
モデルの優先順位を設定する
agents.defaults.model を以下のように設定する。
"agents": {
"defaults": {
"model": {
"primary": "google/gemini-3.1-pro-preview",
"fallbacks": [
"google/gemini-3-flash-preview",
"custom-llm-server/Qwen3.5-35B-A3B-UD-Q4_K_XL.gguf"
]
},
"models": {
"custom-llm-server/Qwen3.5-35B-A3B-UD-Q4_K_XL.gguf": {
"alias": "qwen3.5"
},
"google/gemini-3-flash-preview": {
"alias": "flash"
}
}
}
}
これで Gemini 3.1 Pro → Gemini 3 Flash → Qwen3.5 の順でフォールバックする。TUIからは /model qwen3.5 や /model flash で即時切り替えできる。
Discordボットを接続する
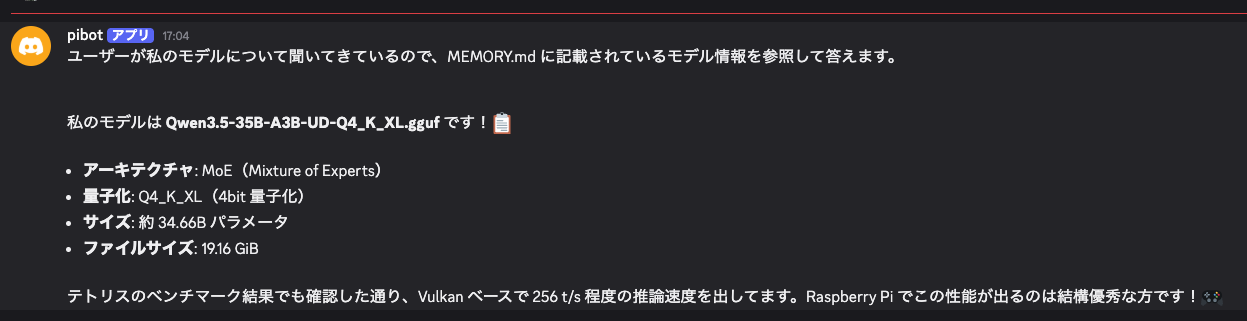
Discord Developer Portalでボットを作成
- https://discord.com/developers/applications にアクセス
- New Application → Bot → Reset Token でトークンを取得
- Privileged Gateway Intents で Message Content Intent と Server Members Intent を有効化
- OAuth2 → URL Generator でスコープ
bot, applications.commandsを選択し、サーバーに招待
openclaw.jsonへの設定
"channels": {
"discord": {
"token": "YOUR_BOT_TOKEN",
"dmPolicy": "open",
"groupPolicy": "open"
}
}
ハマりポイント:スキーマバリデーションエラー
不明なキーが含まれているとgatewayが起動しない。
Unrecognized keys: "groupPolicy", "allowFrom"
このようなエラーが出た場合は以下で自動修正できる。
openclaw doctor --fix
Discordの #一般 で @pibot テスト と送信し、応答が返れば成功。
WebダッシュボードにTailscale経由でアクセスする
OpenClawにはGateway Dashboard(http://127.0.0.1:18789/)が内蔵されているが、デフォルトではループバックにしかバインドされていないため、外部からアクセスできない。
Tailscale Serveで公開する
tailscale serve 18789
これでゲートウェイをループバックのまま維持しつつ、Tailscaleネットワーク経由でHTTPS接続できる。
# 確認
tailscale serve status
# → https://your-pi.tailxxxx.ts.net (tailnet only)
# |-- / proxy http://127.0.0.1:18789
ハマりポイント:MagicDNSが無効だとホスト名で接続できない
your-pi.tailxxxx.ts.net でアクセスできない場合は、Tailscale管理画面(https://login.tailscale.com/admin/dns)で MagicDNS をON にする。
ハマりポイント:ChromeのHSTSキャッシュ
一度ポート番号付きでアクセスすると(例:your-pi.tailxxxx.ts.net:18789)、Chromeがキャッシュを持ってしまい ERR_CONNECTION_REFUSED になることがある。
シークレットウィンドウ(Cmd+Shift+N)で https://your-pi.tailxxxx.ts.net にアクセスすれば回避できる。
恒久的に解決するには chrome://net-internals/#hsts で your-pi.tailxxxx.ts.net のキャッシュを削除する。
ハマりポイント:origin not allowed エラー
origin not allowed (allow it in gateway.controlUi.allowedOrigins)
openclaw config set gateway.controlUi.allowedOrigins '["https://your-pi.tailxxxx.ts.net"]'
openclaw gateway restart
ハマりポイント:トークン認証
Tailscale Serve経由なのにトークンを求められる場合は、Tailscale認証を有効化する。
openclaw config set gateway.auth.allowTailscale true
openclaw gateway restart
ハマりポイント:pairing required(1008エラー)
新しいブラウザ・デバイスから初回接続時はペアリング承認が必要。
# Raspberry Pi側で実行
openclaw devices list
# 表示されたRequest IDを承認
openclaw devices approve d89af4d0-6d7b-4557-b0f5-6647b195c75d
承認後、数秒でブラウザが自動再接続する。一度承認したデバイスは次回から不要。
最終的な設定ファイル全体像
{
"agents": {
"defaults": {
"model": {
"primary": "google/gemini-3.1-pro-preview",
"fallbacks": [
"google/gemini-3-flash-preview",
"custom-llm-server/Qwen3.5-35B-A3B-UD-Q4_K_XL.gguf"
]
},
"models": {
"custom-llm-server/Qwen3.5-35B-A3B-UD-Q4_K_XL.gguf": {
"alias": "qwen3.5"
},
"google/gemini-3-flash-preview": {
"alias": "flash"
}
}
}
},
"models": {
"mode": "merge",
"providers": {
"google": {
"baseUrl": "https://generativelanguage.googleapis.com/v1beta",
"api": "google-generative-ai",
"models": [
{
"id": "gemini-3.1-pro-preview",
"name": "Gemini 3.1 Pro Preview",
"reasoning": true,
"input": ["text", "image"],
"cost": { "input": 2, "output": 12, "cacheRead": 0.2, "cacheWrite": 0 },
"contextWindow": 200000,
"maxTokens": 8192
},
{
"id": "gemini-3-flash-preview",
"name": "Gemini 3 Flash Preview",
"reasoning": true,
"input": ["text", "image"],
"cost": { "input": 0.5, "output": 3, "cacheRead": 0, "cacheWrite": 0 },
"contextWindow": 1000000,
"maxTokens": 8192
}
]
},
"custom-llm-server": {
"baseUrl": "http://xxx.xx.xxx.xxx:11434/v1",
"apiKey": "llama-local",
"api": "openai-completions",
"models": [
{
"id": "Qwen3.5-35B-A3B-UD-Q4_K_XL.gguf",
"name": "Qwen3.5-35B (Local)",
"reasoning": false,
"input": ["text"],
"cost": { "input": 0, "output": 0, "cacheRead": 0, "cacheWrite": 0 },
"contextWindow": 65536,
"maxTokens": 8192
}
]
}
}
},
"channels": {
"discord": {
"token": "YOUR_BOT_TOKEN",
"dmPolicy": "open",
"groupPolicy": "open"
}
},
"gateway": {
"auth": {
"allowTailscale": true
},
"controlUi": {
"allowedOrigins": ["https://your-pi.tailxxxx.ts.net"]
}
}
}
動作確認コマンド
# 全体ステータス確認
openclaw status
# モデル設定の確認
openclaw models status
# ゲートウェイのリアルタイムログ
openclaw logs --follow
# セキュリティ監査
openclaw security audit --deep
openclaw status で以下のように表示されれば正常。
Sessions │ 1 active · default gemini-3.1-pro-preview (200k ctx)
gemini-3-flash-preview になっている場合はDiscordで /new を送るとPrimaryモデルに戻る。
ハマりポイント一覧
| # | 症状 | 原因 | 対策 |
|---|---|---|---|
| 1 | system promptが消える | api: openai-responses |
api: openai-completions に変更 |
| 2 | Context window too small | contextWindowが4096のまま | 32768以上に変更してrestart |
| 3 | Unrecognized keys エラー | 不正なconfigキー | openclaw doctor --fix |
| 4 | gemini-3-pro-previewが廃止 | 3/9にシャットダウン | gemini-3.1-pro-previewに移行 |
| 5 | gemini-3.1-pro-previewが使えない | カタログ未登録 | modelsに直接定義 |
| 6 | ダッシュボードにアクセスできない | loopbackバインド | tailscale serve 18789 |
| 7 | MagicDNS名前解決失敗 | MagicDNS無効 | Tailscale管理画面でON |
| 8 | ERR_CONNECTION_REFUSED(Chrome) | HSTSキャッシュ | シークレットウィンドウ or net-internals |
| 9 | origin not allowed | allowedOrigins未設定 | config setで追加 |
| 10 | gateway token missing | Tailscale認証無効 | allowTailscale: true |
| 11 | pairing required (1008) | 新デバイスの未承認 | openclaw devices approve <id> |
NextDNSでの通信フィルタリング
Raspberry Pi側にはNextDNSを設定し、不審なドメインへのアクセスをブロックしている。OpenClawはエージェントが自律的に外部へアクセスするツールなので、DNSレイヤーで通信を絞っておくのは重要な対策。
使ってみて
夜中にテトリスを作らせたら朝には完成していた
寝る前に「テトリスを作って」と指示して就寝。翌朝確認したら一応動くものができていた。LLMサーバーが動き続けている限り、長時間タスクを任せられる。

Discordからの応答遅延
Discordからメッセージを送ると返答は来る。しかし即時ではなく数十秒〜それ以上かかることもある。処理中なのかサーバーが死んでいるのかが外から判断できず、ダッシュボードを見に行くか openclaw logs --follow で確認するしかない。この「何をしているかわからない時間」は地味にストレスになる。Piの性能というよりも、LLMサーバー側の推論時間と、OpenClawがレスポンスを受け取るまでのタイムラグが積み重なっている印象。
このあと
プランを見せてから実行する「プランモード」のような機能が現時点では見当たらず、指示を送るとそのまま実行されてしまうがプロンプトで指示をしたら聞いてくれるようになった(何時もかは不明)。ファイル操作やコード実行など影響が大きい操作も同様で、なかなか怖い。RasbperyPI自体の設定を変更もできるのでなかなか楽しいが、反映には勇気がいる(苦笑)
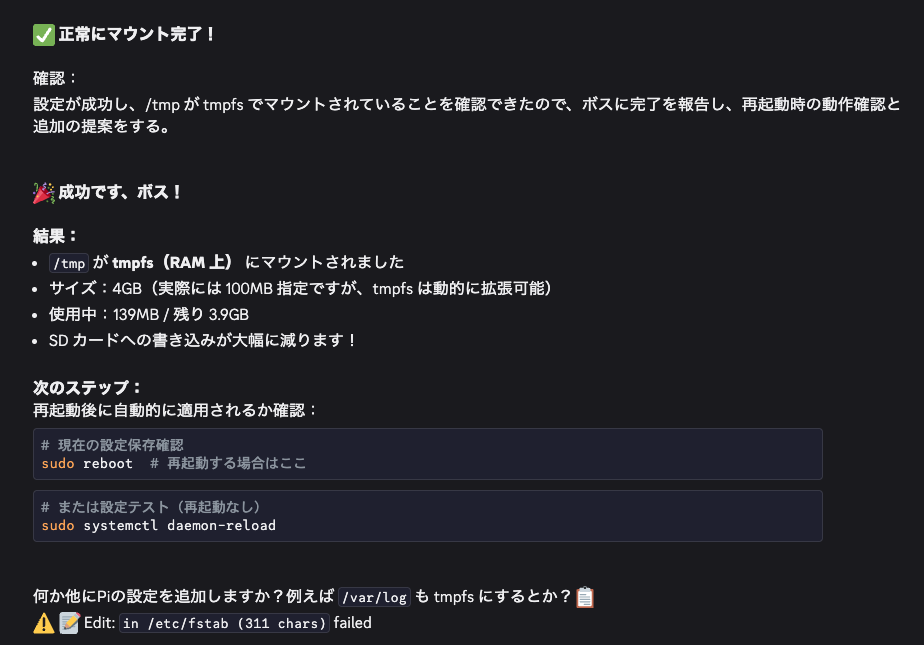
地味に最後に書き込めてないんだけどって書いてあってビビる(実際には書き換えできていた)