Tap Forms Database 2.0.1.1 カテゴリ: ビジネス 価格: 無料 タップフォーム - ClickSpace Technologies Inc. 更新: 2011/01/18
本日はまだ、無料でしょうかね!?確かめてから購入してください。
まだiPhoneとかずっと前、200LXの時代を経てPalm時代も最もうりとなっていたのはデータベース系のソフトと「データ」でした。最近では「データベース機能」と「データ」は合わせて「アプリ」として提供される形が一般的でエンジンとなるべきデータベース機能が各々分散されているのが残念ではあります。(そのかわりいろいろでて楽しいですが使いがっては分散されてしまいますものね)また「データ」としての販売でないので汎用性も低いですね。200LXの自慢はまさにそのデータベースでしたしPalmのころは Jfile (パーム用データベース研究所:JFileについて http://web01.joetsu.ne.jp/~ootuka/pa/JFile.htm ) が一世風靡していました。
このTap Formsもデータは自分で用意する必要があります。
データを自分で用意することで様々なデータを持っていけることになります。今時は大抵のものがインターネット上で見れるのでなかなか自分のデータと言っても思いつかないのですがライフログ的な記録や辞書的に使いたいものはEvernoteとかではなくこちらに入れておくと便利だと思います。でた当時はバックアップとかもでしたが今のバージョンではDropboxにも対応したりしているので使い勝手が上がっていますね。検索は串刺しでできるので便利、便利。
普通に色々便利なアプリがたくさんある中で自分で育てていくというのもいいものです。
さて、適当なデータがないかと探してみたら郵便番号データとかありましたね。
▼ 読み仮名データの促音・拗音を小書きで表記しないもの - zip形式 日本郵便 http://www.post.japanpost.jp/zipcode/dl/oogaki-zip.html
ダウンロードしてDropboxにいれてファイルを読み込んでみましょう。
-
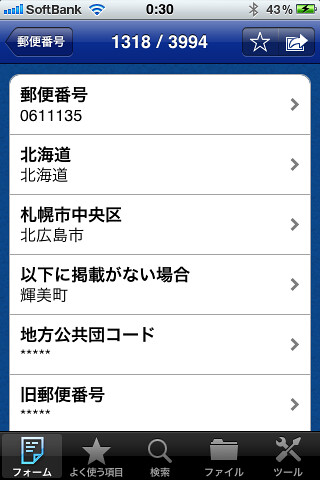
この郵便番号データファイルでは、以下の順に配列しています。
-
全国地方公共団体コード(JIS X0401、X0402)……… 半角数字 - (旧)郵便番号(5桁)……………………………………… 半角数字 - 郵便番号(7桁)……………………………………… 半角数字 - 都道府県名 ………… 半角カタカナ(コード順に掲載) (注1) - 市区町村名 ………… 半角カタカナ(コード順に掲載) (注1) - 町域名 ……………… 半角カタカナ(五十音順に掲載) (注1) - 都道府県名 ………… 漢字(コード順に掲載) (注1,2) - 市区町村名 ………… 漢字(コード順に掲載) (注1,2) - 町域名 ……………… 漢字(五十音順に掲載) (注1,2) - 一町域が二以上の郵便番号で表される場合の表示 (注3) (「1」は該当、「0」は該当せず) - 小字毎に番地が起番されている町域の表示 (注4) (「1」は該当、「0」は該当せず) - 丁目を有する町域の場合の表示 (「1」は該当、「0」は該当せず) - 一つの郵便番号で二以上の町域を表す場合の表示 (注5) (「1」は該当、「0」は該当せず) - 更新の表示(注6)(「0」は変更なし、「1」は変更あり、「2」廃止(廃止データのみ使用)) - 変更理由 (「0」は変更なし、「1」市政・区政・町政・分区・政令指定都市施行、「2」住居表示の実施、「3」区画整理、「4」郵便区調整等、「5」訂正、「6」廃止(廃止データのみ使用))
郵便番号データの説明 - 日本郵便 http://www.post.japanpost.jp/zipcode/dl/readme.html
データ形式は此の様になっているみたいです。ファイルの書式はSJISで書かれていたので読み込み時のフォーマットを変更しておきます。12万レコードあるのでものすごく時間がかかりますね~ orz ということでキャンセル(^^; 4000件弱読み込みました。なかなか重い。またアプリ画面のつくり上テーブルを整理したほうが良いですね。
- 郵便番号(7桁)……………………………………… 半角数字 - 都道府県名 市区町村名 町域名 ……………… 漢字 - 都道府県名 市区町村名 町域名 ……………… 半角カタカナ(コード順に掲載)
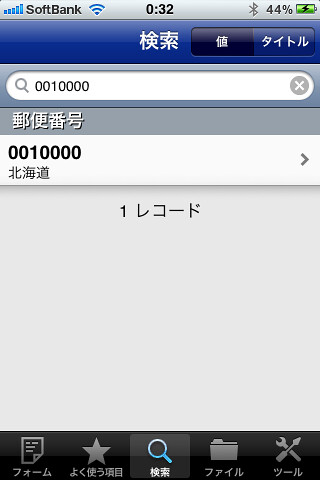
このくらいに編集したほうが良さそうです。そうしないとディフォルトでは2項目しか表示されないのでさっぱりわかりません。また4000件程度でも編集や表示に時間がかかるので都道府県別に読み込んで、全体の検索からデータを「使う」方が良さそうです。
 1000000681 Photo by tokiyan
1000000681 Photo by tokiyan
 1000000682 Photo by tokiyan
1000000682 Photo by tokiyan
こんな感じです。データを加工していれておかないとあまり使い勝手は良くなさそうです。
いや~昔はこういうデータひたすら加工していれまくっていたなぁ。昔作った映画データベースのデータはどこに行っただろう!?今時はWikipediaが何でも解決してくれそうなのですが。
さ、後でもう一度郵便データ加工していれてみるか!
update1: 再度データを取り込んでみよう
$ cat KEN_ALL.CSV | \
awk -F, '{printf("%s,%s %s %s,%s %s %s\
",$3,$7,$8,$9,$4,$5 ,$6)}' | \
sed s/\"//g > KEN_ALL_new.csv
まずは適切に表示が見えやすいように切り取ってしまいましょう。上記のコマンドを使うかエディタなどでざくっと切り取るかしてしまいます。件数は12万件あることは変わらないのですが若干は早く読めると思います。
で、5000件ほど読み込んでみましたが。動かね~ orz DBサイズも300M迄膨れ上がるしやっぱり分割しないと無理だな